128k whitespace tokens, by accident: debugging the Responses API
tldr: I made setting max_output_tokens a hard rule for the Responses API. While generating some structured output, I hit a bug that generated 128k tokens. Removing the array length constraint fixed it!
Always set the max_output_tokens request parameter in the OpenAI Responses API. This is my new rule.
While testing phrasebook-fr-to-en CLI, for some reason the API generated 128k tokens, the maximum. I expected a JSON like this:
{
"translations": [
{
"french": "fr2",
"english": "en2"
},
{
"french": "fr3",
"english": "en3"
}
]
}
I used their structured output feature and defined the expected JSON schema with this Pydantic model:
# DON'T USE THIS CODE. IT MAKES THE REPSONSES API BUG.
from openai import OpenAI
from pydantic import BaseModel, conlist
client = OpenAI()
class Translation(BaseModel):
french: str
english: str
class Translations(BaseModel):
# BUG CAUSED BY THIS FOLLOWING LINE
translations: conlist(Translation, min_length=2, max_length=2)
response = client.responses.parse(
model="gpt-5.2",
input="Il est beau. -> He is handsome.",
text_format=Translations,
)
But what I got was an incomplete JSON with more than 63,000 whitespaces. In total, it hit exactly 128k tokens. If I had set the max_output_tokens request parameter to 256, it would have stopped at 256.
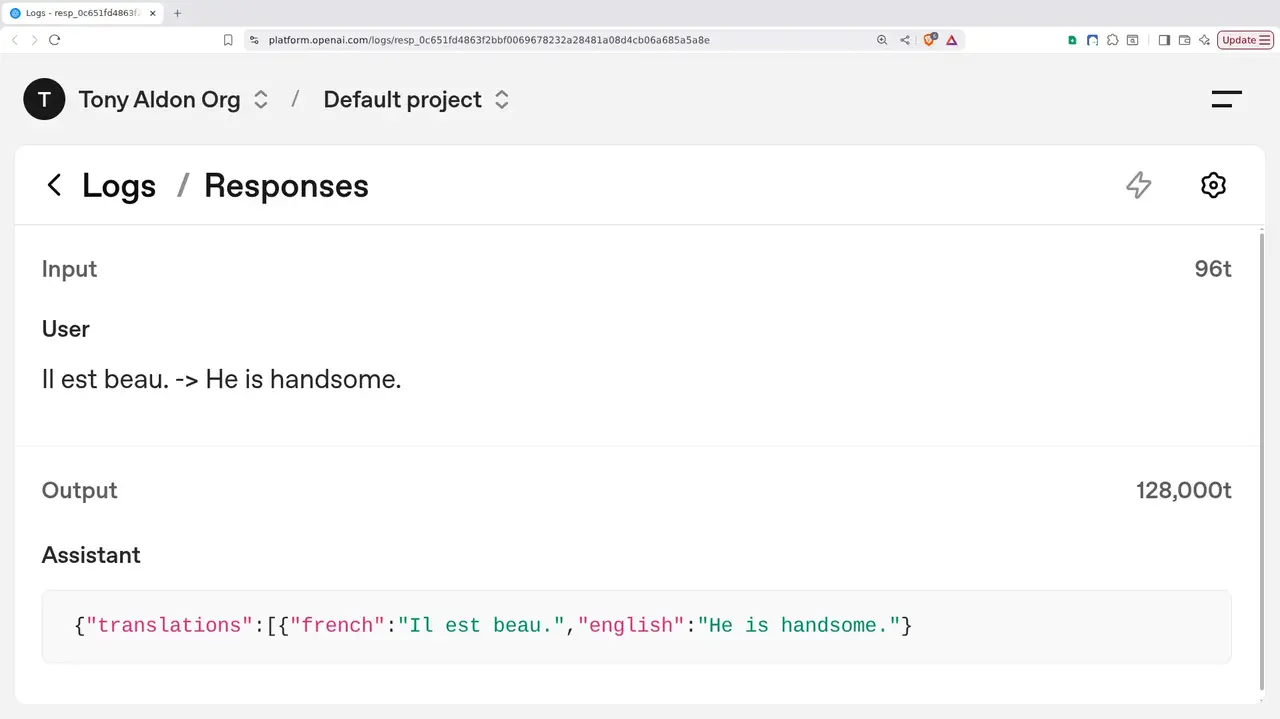
The bug seems to kick in because of the minItems and maxItems array fields in the JSON schema. I set both to 2 with conlist(Translation, min_length=2, max_length=2) in the Pydantic model. Per the docs this should have worked:

And it did, once I removed the length condition on the array, the API responded the right way:
Lesson learned:
Always set the
max_output_tokensrequest parameter in the OpenAI Responses API.
That's all I have for today! Talk soon 👋